The Problem
As analysts, we often get requests that stem from an existing Excel-based process. For example, they might copy data from one source, run some formulas, vlookups, or pivot tables to come to an output that they can send in an email. As the process gets more and more complicated and built-up, you sometimes come across macros being used or matrix functions - where the author is long gone (and so, is no longer maintainable by the team). On the Analytics Team, we generally stayed away from these kinds of things - because (extremely frankly) Excel macros aren't really our specialty and we don't want them to be. However, after years of avoiding the issue and understanding the needs/risks/time waste of these processes, I decided to take matters into my own hands and convert some of these processes to maintainable Python code.
v0.1 - Google Colab
The first processes that I worked on were those where we had a workflow that went something like this:
- User gets data from a third party source.
- User copy and pastes the data into Excel.
- User processes the data in some ways (ie: standardizing it, removing empty rows, etc...)
- User runs some formulas/macros to create an output/report.
The key to the initial version of this tool was that it wasn't combining the external data with any internal data. This meant the logic could be coded into Python and run anywhere. We decided to put the logic in Google Colab. This way, the user could run it any time without having to get infrastructure to create a Python environment and maintain that (which we saw as a potential deal-breaker). Google Colab provides an API to allow users to upload documents:
print('***')
uploaded = files.upload()
filename = ""
for fn in uploaded.keys():
filename = next(iter(uploaded))
print('***')
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn]))) ```
So, the user would execute this cell in the Colab Notebook, upload the document, run the logic - which would do some normal, Python data processing using whatever packages we're using on a daily basis, and then it automatically downloads the file in the end.
```filetosave = f'thefilename-{datetime.now().strftime("%Y%m%d-%H%M%S")}.csv'
df.to_csv(filetosave)
files.download(filetosave)code block```
This logic was able to cut down on data processing time by several hours per *week*. This meant that automating just 10 of these jobs could theoretically save a whole humans-worth of time. We ended up making 4 jobs in Colab - it's a great tool, but there are two problems:
1. Discoverability: We'd link to a shared Colab notebook and users had to save the link somewhere (ie: bookmark it). This meant that for onboarding, these links had to be shared between users or kept in internal process docs. Not great. If we get more and more jobs, it could even be difficult for our team to manage them.
2. Including Internal Data: Colab is outside of our corporate network, so it can only run jobs that are self-contained (ie: data + logic is outside the network).
v1.0 - MacroMouse
Using Google Colab proved out the idea - it truly saved our business partners a lot of time (2-4 hours per week per job). However, now, I was worried about getting a deluge of similar requests from business partners and people talking about this project - and I did. So, I wanted to make the following changes to allow the project to scale out a bit.
- Make the jobs accessible to anyone who wanted to use them without having to manually share links.
- Set up the project like any others - with CI/CD and a single codebase, so that it's maintainable and easy to see what is changing.
- Enable other team members to contribute to the project.
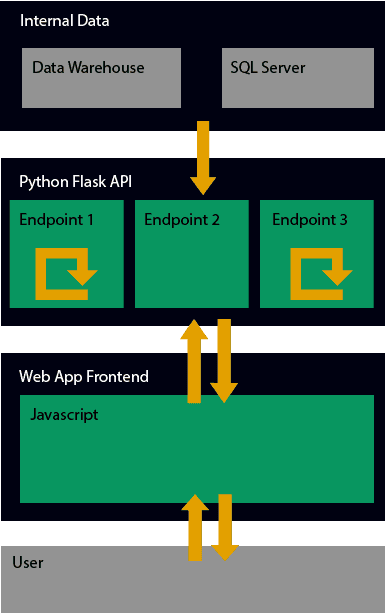
To meet these goals, I created a frontend app (using C# and JavaScript) where the user would go to find and run all the jobs we've created. I also created a database table of the jobs with some basic info about the job - who requested it, what the job was for, what are the expected inputs and outputs, etc. Finally, I made a Python Flask API to hold all the logic - where each job has its own endpoint. The user uploads the required files (if relevant), the data is processed, and the app automatically downloads the output.
So, that's where the project is now - we have about 20 jobs running like this and it's been a great success. Since this is largely outside the scope of our team, the long-term maintenance responsibility will be handed off to another team, but we'll largely be responsible for creating these jobs as needed, given our Python expertise in the team.