Intro
Over the last 3 years, I've been on our analytics team continuing to push us forward as a team, adopting best practices from the data science and software development communities. I've outlined the high-level ideas below.
- Code Repo
- Code Reuse
- Project templating
- Continuous Integration & Continuous Delivery (CI/CD)
- Machine Learning Platform
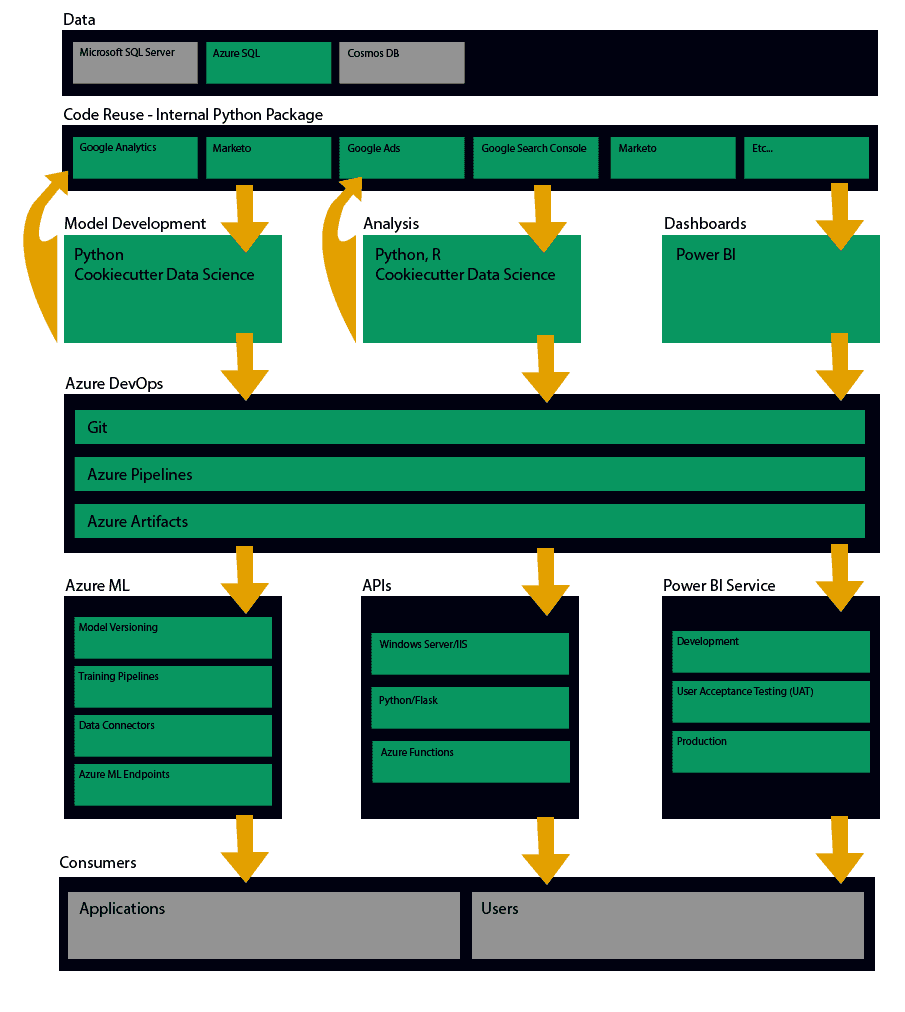
The Platform
Below, I go into detail on each use case we've met with this platform.
Storing Data
Previously, we had a tough time storing data in our on-premises SQL Server. We had two issues - first, our data engineering team owns the database itself, and we didn't have permission to save data in production unless it fit into the rigid, standardized Data Warehousing paradigm - which this very commonly didn't. This meant we couldn't store intermediate outputs that we wanted to report on or persist long-term for whatever reason. Because of this, I helped the team adopt and manage an Azure SQL instance. We now store data for several applications and all of our machine learning needs in Azure SQL. This integrates nicely with Azure ML - which has access to our Azure SQL server. We were also able to be a case study for other teams - demonstrating all the benefits of Azure SQL like automatic scaling, geo-replication, easy backups/restores, etc.
Code Sharing & Reuse
I've built out APIs several times to allow analysts and business members to access our third-party marketing data in C# (.NET), Azure Functions, and Python. Our current iteration of this is an internal Python package that allows analysts to make data requests from a bunch of platforms - without having to have any knowledge of the APIs, authentication, etc... for each platform: Google Analytics, Marketo, Bing Ads, Google Ads, Google Search Console, Bing Webmaster Tools, and several others. I have also added some convenience functions to easily query and add data to internal databases like our on-prem Microsoft SQL Server, Azure SQL, and Cosmos DB. The team can contribute to the codebase fairly naturally due to the way Cookiecutter Data Science's project is set up - creating a mini package itself.
Analysis Template Standardization
I've worked to adopt and promote the use of Cookiecutter Data Science. This is a python package that creates a project template for you. It gives you folders for data, models, notebooks, src, etc... and creates commonly used files - like a requirements.txt, gitignore, etc... With this template, the analyst is always writing their logic into the src folder (as .py files), which makes a local package that can be consumed in your notebooks - for a much cleaner analysis that can be used for business presentations. This encouragement means you can easily contribute your src code to the internal Python package pretty easily (often just by copying the file over).
CI/CD
We have CI/CD for EVERYTHING. This allows us to automate mundane, low-risk tasks (like automated deployment) and gives us a ton of monitoring and maintenance functionality since we don't have a dedicated DevOps team - like knowing what Git commits were part of which version of the code, what version is in what environment, and being able to roll back with 1 or 2 clicks.
- **Internal Python Package: **Builds the package, automatically deploys to dev immediately, and automatically goes to prod weekly.
- Power BI: Reports are automatically deployed to "dev" when you check in your code. When you're ready for UAT, you can automatically promote it to UAT environment, and when you're ready for production, you can press a button and go to prod.
- Pipelines: We have several pipelines - logic that needs to run on some cadence. These are set up similarly - automatically deploying to dev for testing and 1-click production deployment.
- Azure ML: All of our models that train in Azure ML are automatically deployed to dev, and have a 1-click deployment to production.
- Flask APIs: Are automatically deployed to development environment on-premises and has 1-click promotion to UAT or prod. They're used internally only.
- Azure Functions: Same deal.
Azure ML Platform
Azure ML allows us to schedule and monitor our machine learning model training. Often, models are trained daily or weekly and we use this platform to orchestrate all the little steps that go into training a model - data acquisition, data manipulation, model training, model evaluation, and making prediction data or other outputs. Azure ML pipelines handles making connections to Azure SQL databases, storing logs, storing intermediate data, data versioning, model versioning, and model deployment to an API endpoint. It's an extremely powerful and convenient part of our stack.
What's next?
Take full advantage of Cookiecutter Data Science
Cookiecutter Data Science sets us up for our next steps - we want to add automatic project documentation (using Sphynx) and utilize Makefiles to create Python virtual environment and manage dependencies.
Monitoring
Additionally, we're going to get into better model monitoring building it into our pipelines or using a platform like Grafana or Prometheus.
ML Platform?
We may also reevaluate using Azure ML. It has some nice features, but the development experience isn't great. It has a lot of SDK-specific code we have to add to our pipelines and there's no way to test-run your pipeline locally. Going open-source with ML Flow is an option.