Bagging - What?
Bagging is a portmanteau of Bootstrapping and Aggregating. The general idea is that you bootstrap your data (by creating some synthetic data), then train some weak learners on the synthetic data, and finally aggregate the results of the weak learners. This is usually done to high variance/noisy data - to reduce the variance.
Algo Stats
**Performance: **Fast, depending on hyperparameters, but not suitable for real-time applications.
**Interpretability: **Low
Versatility: Extremely versatile - can be used on just about any aggregate values.
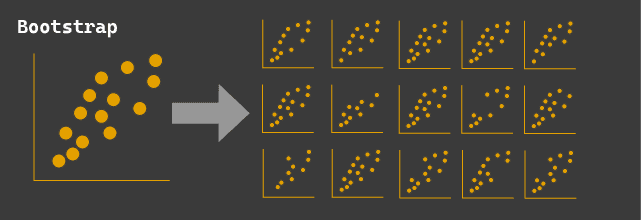
Step 1: Bootstrapping
Bootstrapping is the process of creating synthetic data from an existing dataset. You might do this in cases where you have some experimental data that is representative of a population, but do not have the time or money to run the experiment many times to see how the result changes over many iterations. So, you create random samples of the data (with replacement, so some data points might be duplicated).
For example, if you had website conversion rates before and after a website change - you could use bootstrapping to create additional datasets and aggregate the average conversion rate to see what the distribution of conversion rates may have looked like if you ran the experiment 1000's of times. Using these data, you could determine if the change had a statistically significant difference (ie: passes the Null Hypothesis with 95% confidence) by calculating the 95% confidence interval on the conversion rate and seeing if 0 is within that range. If 0 is in the range, then you couldn't reject the null hypothesis that the change made no difference.
When is bootstrapping awesome?
- When you want to test any aggregate value of a dataset.
- When you'd love to run an experiment many times, but don't have time or money.
- When you have enough data that the sample is likely representative of the whole population.
- When data is not normal, making it difficult to do other techniques.
- When you have aggregate values that don't have a standard calculation (like PCA or R²)
What are some pitfalls?
- This method is problematic when the parameter is biased. For example, standard deviation - you can get around this by using balanced bootstrapping to adjust the values.
Step 2: Training a Model
The next step is to train an ensemble of weak models to predict an outcome. Weak models are generally those that do barely better than a naive approach (like a coin flip). They're simple, explainable, and super fast on their own. These weak models are often trained in parallel, completely unaware of each other.
As an example, a Random Forest is an extension of Bagging - it trains many independent decision trees and has them 'vote' on the outcome.
Note - for models without an element of randomness, this method doesn't really work. For example, if you tried to train many weak linear regression models, they'd all predict the same result - and vote the exact same way. The reason Random Forests make meaningful voting models is that there is an element of feature randomness introduced to avoid overfitting or underfitting the data.
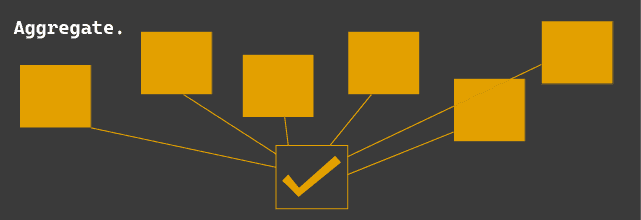
Step 3: Aggregation
Finally, the models aggregate the various outcomes (vote) into a single prediction.
Voting
- Hard Voting: The most votes wins - ie: for classification.
- Soft Voting: The average value wins - ie: in regression.